It’s time for the fourth post in our on-going series about the architecture of CruzDB. In the previous post we took a detailed look at transaction processing and what exactly is happening when a transaction intention in the log is replayed. We saw how a commit or abort decision is made, and how a new database state is created when a transaction commits. In this post we take a look at the challenge of increasing transaction throughput by writing database snapshots in parallel.
Afterimage production
Previously we discussed the copy-on-write structure of afterimages, and began to describe how afterimages are produced by the transaction processor as it analyzes and replays each intention in the log. But so far we have mostly glossed over the details about how these snapshot afterimages are managed, and how they make their way into the log. Here’s the agenda for this post:
- Transaction processor afterimage output
- Managing persistent pointers and tree node eviction
- Efficient, parallel serialization and I/O of afterimages from memory
- Intention node pointers
We’ll start with a description of the output of the transaction processor. The following diagram shows a series of afterimages that have been produced by the transaction processor. In effect, the transaction processor turns a series of intentions from the log into a stream of output afterimages, which are initially stored in memory. This process occurs continuously and in parallel on all database nodes as the log is scanned. It’s important for the throughput and latency of the system that the transaction processor be able to generate these output states in memory and make progress by replaying intentions against in-memory snapshots without having to wait on afterimages to be synchronously written back into the log.
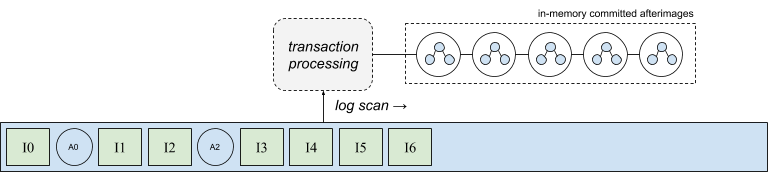
Of course a real database will be continually changing through the replay of new intentions found in the log. As the set of afterimages produced by the transaction processor grows, memory pressure will increase and it will be necessary to free memory so that the transaction processor may continue to make progress. In order to maintain system throughput afterimages must be efficiently moved into stable storage, becoming available for eviction, and keeping memory pressure in check. However, as we’ll discuss in the remainder of this post, there are challenges to making afterimage I/O efficient.
Persistent pointers
Recall from the second post in this series about copy-on-write trees that serializing the afterimages into the log provides numerous benefit such as avoiding intention replay, and sharing database state across clients. Perhaps most importantly, this allows a shared-data architecture in which infrequently used partitions of the database state to be freed from memory, and paged-in on-demand, eliminating the need for every node to maintain a full replica of the database. These materialized views in CruzDB originate as afterimages produced by the transaction processor, as we just saw above. But serializing these afterimages from memory and into the log is not as simple as it may seem due to the conflicting requirements of fast, parallel I/O and dependencies between afterimages in the form of node pointers.
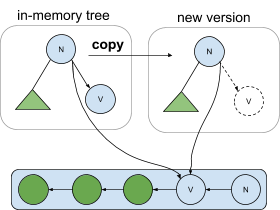
To fully describe the challenges that arise, more detail is needed about pointers and how they are managed in copy-on-write trees. Recall that the afterimages in CruzDB are structured as a copy-on-write tree. One aspect of a copy-on-write tree is that new versions of the tree share common subtrees with past versions using child pointers in nodes that point at shared subtrees. As nodes are copied to build new versions of the tree, these shared subtree pointers are also copied, and are only changed when the contents of a shared subtree diverge.
Consider the following diagram. On the left is an in-memory tree which might represent the latest committed state of the database. The root’s right pointer targets the node v, and also contains a pointer to the serialization of node v in the log. When a new version of the tree is made (e.g. through replay by the transaction processor), the root pointer is copied, along with both the in-memory pointer to node v as well as the address of node v in the log. The address in the log is immutable, so any number of copies can be made of the pointer, and they will all point to the same serialized version without any synchronization needed. If node v is ever evicted from memory (depicted in the tree labeled new version), any copy of a node containing a pointer to node v can recover node v from the log, even if the deserialized version eventually contains a different address in memory.
Clearly the ability to evict node v from memory relies on an addressing scheme that includes a pointer to a persistent version of the node. But what happens if a node needs to be copied or evicted, but a physical address is not yet known? Recall the copy-on-write structure of the afterimages produced by the transaction processor, shown in the following diagram with node back pointers colored in blue. This figure helps illustrate a conflict between the ability to evict nodes (i.e. the nodes have persistent addresses in the log), and to design a high-throughput transaction processor. As we just saw, a node cannot be evicted unless all its in-memory references also include its physical log address, which cannot be known until it is actually written to the log. On the other hand, the transaction processor cannot wait for a log append to occur before processing the next intention, otherwise performance would degrade to at least the performance of performing synchronous I/O. Thus the first challenge is how to maintain the copy-on-write structure in-memory while allowing nodes to be evicted before they are written to disk.
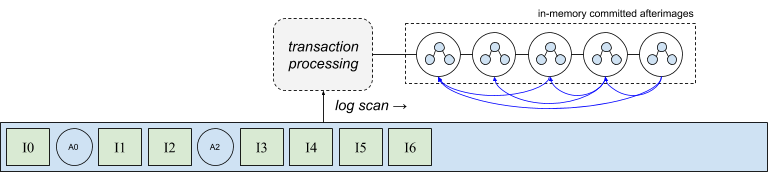
One mechanism is to use a reverse index that tracks every in-memory reference to a node without a physical address. Once the physical address is known, every reference can be efficiently located and updated by examining the index. This approach is worth exploring in terms of the cost of the in-memory data management. However, we’ve taken a different approach in the current version of the system. Before we describe the solution to this issue taken by CruzDB, we’ll look at one additional challenge that is closely related, because both challenges make use of the same solution. This second challenge relates to the process of actually writing the afterimages to the log efficiently.
Efficient serialization
Since the serialization of an afterimage contains pointers to past nodes, it would seem that writing afterimages would need to be, in general, a serial process so that dependent, persistent pointers could be known. Thus, an important question to resolve is how the in-memory afterimages can be written with sufficient throughput, so as to reduce back pressure that could limit transaction processing performance.
The fundamental problem with writing afterimages in parallel is that the physical location of a node cannot be known until it is written, which serializes I/O when writing nodes in afterimages as physical pointers must be resolved. The solution used in the current implementation is to introduce an additional pointer type that expresses a node address in terms of its intention, which is always known, rather than the direct address of the afterimage. This allows I/O to proceed in parallel, providing a means of addressing the throughput challenge.
Intention node pointers
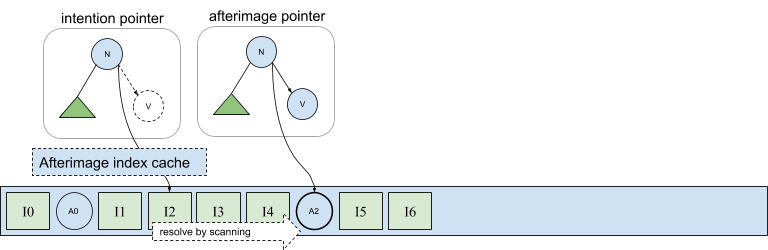
In the following diagram, the tree labeled afterimage pointer shows node n’s right child pointing into afterimage A2 stored in the log. This pointer is expressed in terms of A2’s physical address, which as we have seen, is exactly the information not available during a parallel flush of a set of connected afterimages. However, recall from our discussion about handling duplicate versions of materialized views that the first afterimage in the log following an intention is the active version. Thus, we can uniquely address the afterimage of an intention even before it has been written by simply referring to the intention itself. This is shown in the same figure by the pointer contained in the tree labeled intention pointer in which node n’s right pointer is semantically equivalent to a pointer that instead addresses A2 directly.
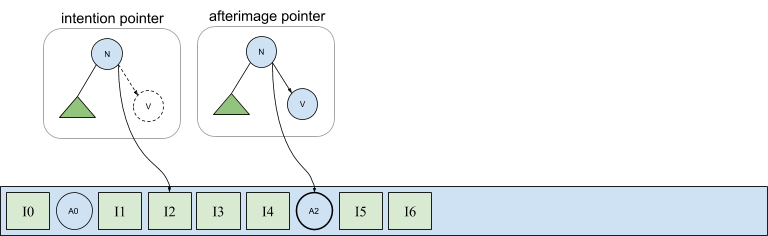
This solution addresses both issues we described earlier. Physical (intention) pointers are immediately available when copying nodes during intention replay, allowing nodes to become available for eviction. And intention pointers can be used to encode physical pointers during asynchronous afterimage flushing. Of course, direct afterimage pointers should be written when available because there are overheads associated with the indirect intention pointers.
Intention pointers can be resolved to their corresponding afterimage by scanning forward from an intention. And since the pointer exists as a result of the intention committing, it is guaranteed that an afterimage will exist (eventually) in the log. However scanning is expensive, so a cached index is used to accelerate intention-to-afterimage translations, as shown below.
With this level of indirection we are able to write afterimages in parallel, but throttling is still important in order to slow the creation of new transactions if flushing is not able to keep pace.
Startup and recovery
We’ll cap off this post with a discussion of database startup and recovery. It’s quite unrelated to the topic of afterimage management, but it is short, and it also closes the loop on the major, high-level aspects of the CruzDB architecture.
A naive approach to starting a database node is to replay the log from the beginning. For a large database, this may represent a significant amount of time and wasted resources. A better approach is to find the latest consistent version of the database, and replay from this point, minimizing the amount of work required to bring the local state of the database node up to date.
The state from which the database resumes is referred to as a safe point, and consists of an afterimage and its corresponding intention. The afterimage provides a snapshot upon which replay intentions, and the corresponding intention defines the point from which the log should be replayed. To find the newest safe point, the startup process scans the log from the tail backwards.
Consider the following diagram. Starting from the end of the log and working backwards, afterimage A2 is identified as the latest afterimage, but its intention has not yet been identified. Continuing the scan, the next afterimage encountered is A3. The scan continues, and eventually the scan discovers intention I3 corresponding to afterimage A3. The pair of afterimage A3 and intention I3 form a recent safe point. Duplicates in the log are handled by selecting the oldest version of the afterimage while scanning backwards. Recall that by design, no afterimage for an intention will occur prior to the intention in log order.

Once the database is initialized with A3 and I3, replay may begin. In this case I4, I5, and I6 will be replayed and their corresponding afterimages will be computed and eventually stored in the log.
The gray log entries in the middle of the figure, labeled H, are holes in the log. Holes are positions in the log that have not (yet) been written, possibly due to a slow or crashed node that had been assigned those positions. Recall that the active afterimage of an intention is the first afterimage in the log following the intention in log order. While A3 is the first afterimage following I3 at the time of recovery or start-up, in-flight I/Os directed at one of these holes may complete after startup. If one of these in-flight I/Os is another afterimage of intention I3 then the state that the database was initialized with will become stale. While existing duplicates are handled by performing a full scan backwards to the target intention, we must make sure that in-flight duplicates do not invalidate our decision.
In order to guarantee that the initialization state remains correct, the startup and recovery process will fill the holes in the log to prevent any future log entries from being written to these locations.

Once all holes have been filled, if the choice of initialization state has not changed, the log may be replayed and normal database operation may resume.
In the next post we’ll take a short look at how the database catalog is implemented in CruzDB. Looking forward further, the next major release in this series will discuss garbage collection and how free space in the log is managed.
And a special thanks to Jeff LeFevre for providing feedback and edits on this post.