This is the second post in a series of articles examining the architecture of CruzDB. In the previous post we examined the basics of how transactions are stored in an underlying shared-log, and began to discuss the distributed operation of the database. In this post we are going to examine how the database is physically stored in the log as a serialized copy-on-write binary tree. In addition, we’ll cover some complications that appear in a distributed setting such as duplicate snapshots, and how they are handled.
Fine-grained snapshots
Recall from the previous post that intentions are representations of transactions that have not yet committed or aborted. In CruzDB, each database node replays intentions in the log and deterministically determines the fate of each transaction. As intentions are replayed by database nodes, new versions of the database are created. In order to avoid forcing all database nodes to store a copy of the entire database, CruzDB stores fine-grained snapshots in the underlying log providing shared access to past database states to clients and database nodes. The remainder of this post will examine the structure of these snapshots.
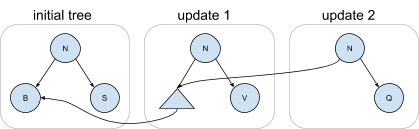
CruzDB stores the entire database contents as a copy-on-write binary tree. A copy-on-write binary tree is a binary tree in which any update forms an entirely new root where unmodified subtrees are shared with previous versions of the tree. This allows CruzDB to generate fine-grained representations of new database snapshots that result from committing a transaction and replaying its intention.
The following diagram shows an example of a copy-on-write binary tree. The initial tree contains three nodes. The new tree labeled update 1 is created by applying a set of changes to the initial tree. In the resulting tree, both the left and right children have changed after the update. However, node B from the initial tree is shared through a path accessible from the root of the new tree, as shown by the edge connecting the two trees. Likewise, the tree produced by update 2 has its right child updated, but its entire left subtree is shared with the previous tree.
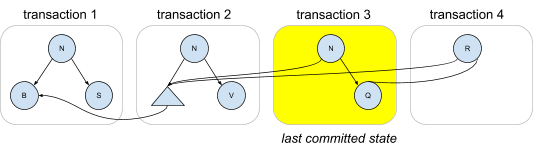
The structure of a copy-on-write tree is particularly well-suited for representing the fine-grained updates that CruzDB requires. Tying this discussion back to the description of replaying log intentions, consider the following diagram in which the first three tree versions are computed by replaying the intentions from a series of transactions. The third transaction is the last committed state, and a new intention for transaction 4 is replayed, producing a tree with a new root that shares both left and right children with the previous last committed state. Note that this is just an example; the actual structure of the trees in a particular database is dependent on the set of nodes being updated in each transaction, the history of transactions that are replayed, and any restructuring that occurs due to rebalancing.
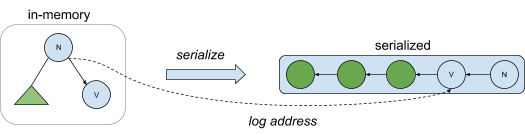
In CruzDB each of these trees is referred to as an afterimage. As database nodes replay intentions from the log afterimages are produced locally in-memory. Over time memory pressure will increase, and subsets of the in-memory representation of the tree will need to be removed. However, instead of simply removing the nodes from memory (which would be particularly problematic!), CruzDB stores subtrees in the log so that they can be accessed in the future without having to incur the costs of replaying the log.
The following diagram depicts serialization of an in-memory afterimage into the log. Tree nodes contain both an in-memory pointer, as well as an address in the log that can be used to restore the in-memory representation when needed. That is, if a node in memory contains a pointer to a child node that exists in the log but which is not resident in memory, the child node can be reconstructed by following the pointer to a persistent version of the node found in the log. Afterimages are serialized by the transaction management process, which is covered in the next post in this series.
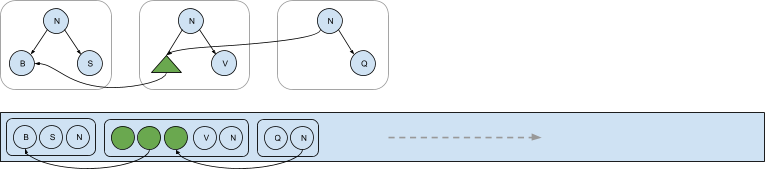
The serialization process also takes care to correctly maintain pointers between serialized afterimages. Each time a new afterimage is serialized into the log, it will point to previous afterimages that contain shared subtrees. The following diagram shows three dependent afterimages serialized into the log that contain pointers to nodes located in previous afterimages that have been serialized.
By ensuring that afterimages in the log are linked to the transactions and intentions that produced them, database nodes can efficiently access old snapshots. This allows point-in-time queries, and scale-out processing of read-only long running queries. As we’ll see in the next post on transaction management, having access to the afterimages in the log forms the basis for quickly bootstrapping a database node, and allows partial copies of the database to be cached while still being able to efficiently reconstruct any subset of the database on-demand. Next we’ll look at the basics of how afterimages are managed in CruzDB.
Afterimage management
There are many scenarios that CruzDB must handle when managing afterimages. Let’s start with some simple cases and build up from there. The following diagram shows a simple scenario broken down into three steps. Initially the log contains the single intention I0 (step 1). Next, a database node replays the log, and with it the first intention I0, producing the after image A0 in memory (step 2). Finally, the database node serializes the afterimage and writes it back to the log (step 3). Once the afterimage has been written to the log, the database node may choose to keep the nodes in A0 from the afterimage cached locally in memory, or release them and restore them later from the log if needed.
Afterimages are only produced when an intention is replayed from the log, and the intention experiences no conflicts. Therefore, afterimages always appear in the log after the committed intention from which it was produced. Thus, to encode the association between afterimages and intentions, afterimages include a reference to the intention that produced it. This reference is included in the serialized representation of an afterimage, as shown by the backpointer from A0 and I0 in the following diagram.

Like we saw in the previous post describing the distributed operation of CruzDB, any number of database nodes may be operating in parallel, producing the same set of afterimages. The system is designed to be deterministic, so all nodes produce the exact same set of afterimages.
Asynchronous I/O
Notice in the previous diagram that immediately after replaying intention I0 that the database node contains the latest committed state, A0, in memory. This snapshot is the same regardless of it has been serialized to the log or not. Thus, the node already contains the state necessary to replay more intentions, or run its own transactions.
Consider the scenario shown in the next figure, in which the database node appends a new intention I1, has generated the corresponding afterimage A1 in memory, but not yet written A1 to the log. Requiring that A1 be written to the log before the next intention is handled would introduce an expensive I/O serialization requirement, given that afterimages are replayed in the same order that they appear in the log.
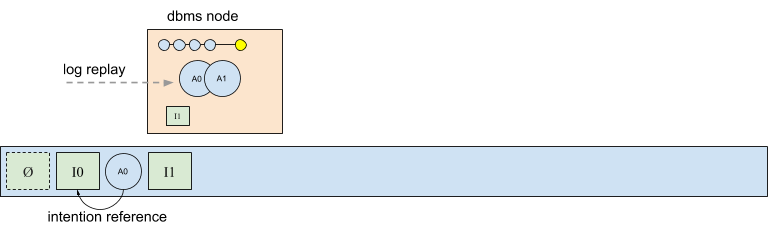
Instead, CruzDB allows afterimages to be serialized and written to the log asynchronously, taking advantage of the observation that generating and managing afterimages in memory can be significantly faster than serialization and I/O latency. As a result, afterimages can also be written in parallel, and combined into more efficient, larger I/O operations.
Since afterimages are written asynchronously, they become partially ordered in the log with respect to their intentions. In the following diagram intentions I2 an I3 have been written to the log, and the after images for I1, I2, and I3 have also been written, although their ordering is non-deterministic in the sense that afterimages may be appended concurrently and their final ordering is not known at the time they are appended. For example, below A1 could have been written before I3, or A1 could have landed in the log after A3. However, A3 could not, for example, appear in the log before its intention I3.
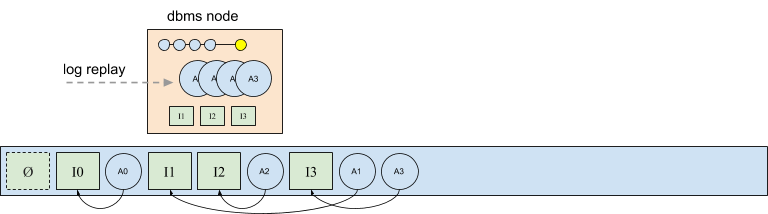
The complexity introduced by storing afterimages in the log, and the effect on operations in a distributed deployed is only minor. During replay, every node produces identical in-memory snapshots. Since afterimages are allowed to be delayed and written asynchronously, anytime a database node encounters an afterimage in the log, the address of the afterimage in the log may be used in lieu of writing a new copy of the afterimage.
This leads naturally to a policy decision regarding the responsibility of writing afterimages. A simple policy is one in which the node from which an intention originated is the node responsible for writing the corresponding afterimage. However, a slow, misbehaving, or failed node must be responded to by taking over the role of writing afterimages. This results in the possibility of duplicated afterimages in the log.
Deduplication
Consider the scenario shown in the figure below. Database node 2 appended intentions I1 and I3, and the system uses a policy in which the node that appends an intention is also responsible for writing the corresponding afterimages. However, in this case database node 2 is slow to write afterimages A1 and A3 (shown in red). At some point database node 1 may timeout, and write these intentions itself. This is an example of a common challenge in distributed systems. Policies and techniques for dealing with this are out of scope here, but may be addressed in later posts. But in all cases, it’s possible that duplicates appear if database node 1 decides to write A1 and A3, and database node 2 eventually completes its writes.
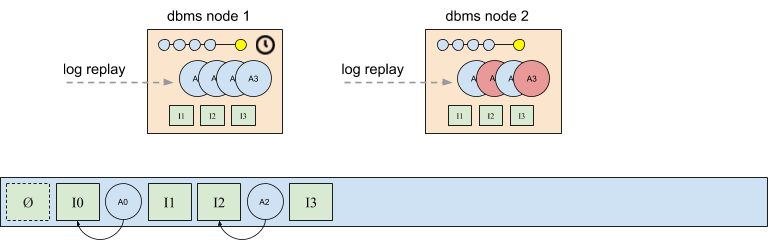
The following figure shows the state of the log after A1 and A3 have each been written into the log twice. Although the duplicate afterimages are logically identical, they are separate physical instances of the same subtree. Thus, if multiple database snapshots that share a common subtree each reference a different physical copy of the subtree, this may result in inefficiencies, as well as complicate tasks like garbage collection. This is why it’s desirable for all participants to agree on the same authoritative (or active) version of an afterimage.
The solution used in CruzDB is to make use of the global ordering property of the log to force all nodes to agree on the same active afterimage. This is done by defining the active afterimage of an intention to be the first afterimage instance in the log (for that particular intention). The bold versions of A1 and A3 in the figure below highlight the result of this policy. Even though the diagram is drawn with the afterimages in order, the policy of selecting the first afterimage yields correct behavior even when the afterimages are written in a different order. For example, if A3 is written before A1 the same decision is made.
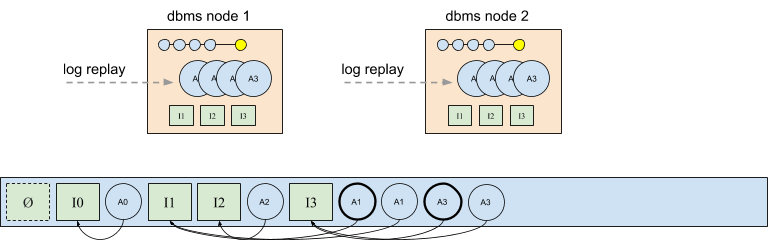
Like concurrent intentions in the log that experience a conflict, duplicate afterimages in the log are completely ignored by CruzDB with respect to the state of the database. Although they may contribute to statistics, the duplicate afterimages are immediately eligible to be garbage collected without affecting any operations. Garbage collection for duplicate afterimages and intentions with conflicts are cheap operations provided by the underlying log that doesn’t require any compaction. There are many other aspects to consider for correct and efficient garbage collection and free space management, but this will be covered in a future post.
In the next post I’ll cover transaction management, including the life cycle of transactions, how conflict zones are retrieved from the log and analyzed, and how the database itself is used to index parts of the log to speed-up transaction processing.
And a special thanks to Jeff LeFevre for providing feedback and edits on this post.