CruzDB is a distributed shared-data key-value store that manages all its data in a single, high-performance distributed shared-log. It’s been one the most challenging and interesting projects I’ve hacked on, and this post is the first in a series that will explore the current implementation of the system, and critically, where things are headed.
Throughout this series we will dig into all the details, but here is a brief, high-level description of CruzDB. The system uses multi-version concurrency control for managing transactions, and each transaction in CruzDB reads from an immutable snapshot of the database. This design is a direct result of being built on top of an immutable log. When a transaction finishes it doesn’t commit immediately. All of the information required to replay the transaction—a reference to its snapshot, and a record of the its reads and writes—are packaged into an object called an intention which is then appended to the log. Any node with access to the log can append new transaction intentions, and replay the intentions in the order that they appear in the log. This process of replaying the log is what determines if a transaction commits or aborts, and because the log is totally ordered, every node in the system deterministically makes the same decision about every transaction.
This is a high-level architectural view of the system. At the top is CruzDB which can be linked directly into an application, or accessed through a proxy. It’s API is similar to RocksDB. In the middle is a distributed shared-log that stores all of the data from CruzDB. The implementation of a shared-log that we use is ZLog which is designed to run on top of a distributed object storage system. While ZLog is designed to run on a variety of distributed storage systems, we use the Ceph distributed object storage system, represented at the lowest level in the diagram.
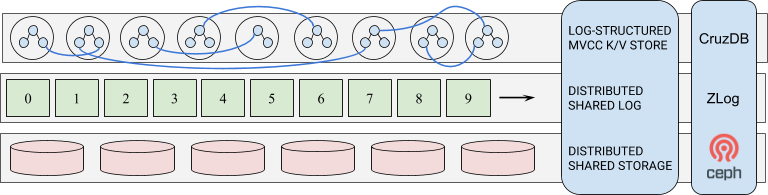
In the remainder of this post we are going to introduce the basic log-structure of CruzDB. After reading this post there should be many open questions, many of which will be covered in subsequent posts in this series on the architecture of CruzDB.
Background
CruzDB started as a small demonstration of using a distributed shared-log as a storage abstraction. It was built as an example for using ZLog which is a research vehicle for various projects in the UC Santa Cruz Systems Research Lab. ZLog is influenced by CORFU, but runs on software-defined storage. See this blog post for more detail about ZLog. The CruzDB project was inspired by the Hyder database system, but CruzDB started out as nothing more than a simple library and API that could be used to serialize a copy-on-write tree into ZLog. See this blog post for a view into the state of CruzDB several years ago.
Over the last few years we have been working on CruzDB and have made significant progress. While the design of the transactional aspects of the system were inspired by Hyder and the follow-on papers regarding its MVCC algorithm (see this, and also this), CruzDB has retained a lot of the same terminology while taking an entirely different approach to transaction management.
Introduction
Every piece of data in CruzDB is stored in a distributed shared-log. Database nodes in the system replay transactions from the log to independently and deterministically reproduce the database state by computing the commit or abort status of each transaction. CruzDB uses a shared-data approach to managing state in order to avoid forcing all database nodes from having to store an entire copy of the database.
In addition to storing transactions in the log, fine-grained materialized views of the database are stored in the log. This allows database nodes to selectively cache database state, while still providing on-demand access to any subset of the database by reading from the log. These views also enable interesting features such as time travel in which any past database state can be examined. This is a particularly useful feature for performing analysis on a consistent state of the entire database. And since each snapshot is immutable, aggressive caching and optimization techniques can be used, even for long running queries, without interfering with new transactions.
Our design is inspired by Hyder which is a database system in which the entire database is structured as a copy-on-write tree that is stored in an underlying distributed shared-log. Unlike Hyder that uses a unified tree structure for the database, CruzDB decouples transaction management from storage, managing transactions separately from the representation of the database. This separation enables certain optimization, and allows the system to support a variety of data structures in addition to its primary copy-on-write tree.
Next we’ll discuss the basic structure of the log, including how transactions are committed or aborted, and the process by which materialized views are created, stored, and accessed. The basic log structure and database operations are relatively quick to introduce, but leave open important questions related to performance and real-world implementation challenges. These questions will be addressed in detail in subsequent sections and posts in this series.
Basic log structure
Every interaction with the database is in the context of a transaction. When a transaction finishes it doesn’t immediately commit or abort. Instead, an intention is created that fully describes the actions of the transaction. In particular, an intention is a record of the reads and writes the transaction issued, and is sufficient for replaying the transaction at a later time. Once an intention is created it is appended to the log. Placing the intention in the log guarantees that the transaction is durable, and allows all nodes in the system to see a global ordering of transactions.

Any past state of the database is uniquely described by a position in the log, and can be calculated by replaying the intentions in the log up to a target log address. For example, the state of the database corresponding to the location in the log containing intention I0 shown above, can be calculated by replaying all transactions in the log up to and including intention I0. In this case, that means replaying only intention I0, since it is the only intention in the log.
Not stored physically, CruzDB implicitly defines the snapshot of the first intention in the log to be the empty database. In the following diagram, the snapshot that intention I0 read is the implicit empty database, depicted by the dotted arrow connector. When I0 is replayed against the empty database, it produces a new database state labeled S0. Note that although shown here, the initial empty database snapshot is generally not illustrated.

The latest committed state is the snapshot of the database that corresponds to the oldest intention (highest log address) that has committed. This state will be illustrated by coloring the snapshot yellow, as shown in the following diagram. Note that the latest committed state is relative to the degree to which a database node is up-to-date with respect to true end of the log. In general the diagrams shown represent a quiescent state that would exist when the log has been fully replayed.

The existence of an intention in the log does not mean that the transaction that created it committed or aborted. To determine the final state of a transaction, its intention is analyzed to determine if any conflicts occurred with respect to other intentions, and the isolation level of its transaction.
The next scenario to consider is shown in the following diagram, in which the state of the log is illustrated after a transaction has finished and its intention I1 has been appended. Notice that the diagram shows that the snapshot of I1 is I0, rather than what one may expect it to be, S0, which was produced by replaying I0. The distinction is subtle; an intention in the log physically records its snapshot as a reference to the intention that produced the state of the database that it read when its transaction started. Critically, the snapshot of an intention may not be the same database state that the intention is eventually replayed against. Later in this series of posts the physical representation of the snapshots will be discussed, and how they are stored and referenced, but for now the abstract form of database state is sufficient for an introduction.
The following diagram show that intention I1 committed and became the latest committed state. Intention I1 is special; it is referred to as a serial intention. An intention is serial if it is the first intention in the log with no conflicts, following its snapshot. In other words, an intention is serial if the latest committed state is the same as the intention’s snapshot. So in this case I1 is serial because its snapshot is I0, and I0 was the latest committed state when I1 was being replayed from the log. Serial transactions by definition do not have any conflicts, and can immediately commit without performing any conflict analysis (other than the work required to determine that it is serial, which is effectively the comparison between two integers representing log addresses).

The existence of serial transactions is highly dependent on the deployment of CruzDB and the active workload. For instance, a single node issuing transactions may experience a high proportion of serial intentions compared to a scenario in which many clients are running transactions in parallel from different physical nodes. An intention in the log that is not serial is referred to as concurrent, and must be analyzed for conflicts to determine if it should be aborted, or commit and have its updates merged into the latest committed state.
Concurrent intentions
An intention in the log is concurrent when the latest committed state is not the same as the intention’s snapshot. Consider the scenario in the following diagram. Shown are four intentions produced by transactions all of whom started with I1 as their snapshot.

Because the transactions execute asynchronously, possibly on other physical nodes a cluster, their final position in the log after being appending is non-deterministic. However, once the intentions have been written to the log, their ordering is fixed and globally consistent; any node will observe the four intentions in the log in exactly the same order. However, for the sake of this exercise, let’s assume they land in numerical order to keep things simple.

Next we’ll look at how the system determines the fate of each intention. Since the intentions in the log are replayed strictly in order, we’ll examine how CruzDB handles each of the four intentions one by one. First up is intention I2.
Although all four intentions were in flight at the same time, I2 landed first by chance. Notice that like I0 and I1, I2 is also a serial intention, which means that it may immediately commit and be applied to its snapshot to produce the latest committed state, shown below as S2.

The next three intentions, I3, I4, and I5 are all concurrent. The following diagram illustrates the concurrent property clearly for I3 in which its snapshot, I1 is not the same as the latest committed state: intention I2 committed and is positioned in the log between the two intentions. The interval in the log that forms between a concurrent intention and its snapshot is referred to as a conflict zone. In the following diagram the intention I2, shown in red, is the only intention in the conflict zone of I3.

Determining if I3 commits requires that its conflict zone be examine to identify any conflicts that may exist. For example, if I2 and I3 both wrote the same key to the database, then I3 will experience a write-write conflict on the common key, causing I3 to abort. In this example I3 lucks out and experiences no conflicts. But unlike a serial intention, notice that the changes in I3 are applied to the database state S2 produced by I2, rather than its snapshot I1. This clearly shows that the snapshot of an intention is only used for computing an intention’s conflict zone, and all intentions are applied in order to the latest committed state.

Consider now the intention I4. This intention is concurrent, and is handled exactly the same as I3. The only difference is that its conflict zone is wider; it includes both I2 and I3. For the purposes of exploring all salient scenarios, consider the case in which I4 experience a conflict and aborts.

The intention I4 is illustrated uniquely below to indicate that it aborted. Any intention that experiences a conflict is completely ignored by the system. It does not alter any state, and for all intents and purposes, can be considered by CruzDB to not exist in the log. In practice all intentions may contribute to system state such as statistics, and in general can be subject to garbage collection. But we are talking about transaction management; in this case I4 aborts, and S2 remains as the latest committed state.

Finally, we arrive at the concurrent intention I5. Its conflict zone contains I2, I3, and I4. However, since I4 aborted, it is not included in the set of intentions that are considered when analyzing I5 for conflicts.

Below shows the final state of the log after determining that intention I5 experiences no conflicts. It is replayed against I3 to produce the next latest committed state. Any node or process in CruzDB that replays the log up to the position that includes intention I5 will deterministically produce the exact same set of states. This property will form the basis for running CruzDB in a distributed setting.

Thus far we have avoided any discussion of the structure of the intermediate snapshots produced by replaying the log, or mentioned important low-level details about how nodes and processes in CruzDB manage database state. After finishing this post by describing the basic distributed operation of CruzDB, subsequent posts in the series will examine these issues in detail, including the copy-on-write tree used to represent snapshots, and how transactions are managed in a distributed setting.
Distributed operation
A distributed deployment of CruzDB refers to any scenario in which independent database clients are operating against the same log. Typically this means distinct physical database nodes accessing the log across the network, but the set of scenarios that result from a distributed deployment may also occur even when multiple database clients are running on a single node. However, we tend to use a phrasing that refers to separate nodes.
The following diagram depicts a distributed deployment where two database nodes are running independently and replaying the log. As shown at the top of each node, the log is replayed in the same order on both nodes thereby calculating locally the exact same series of states. This allows nodes to analyze intentions in the log without any required coordination.
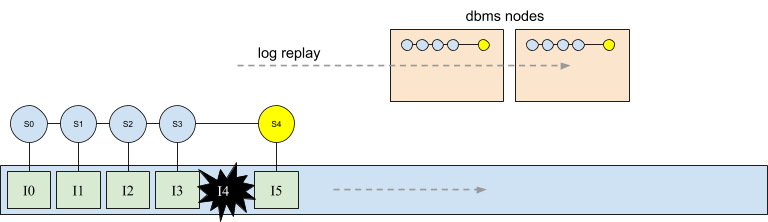
This is a good opportunity to clarify the details about where state is stored in the system. Until now, each intermediate database state (i.e. S0 … S4) has been drawn above its corresponding intention in the log. While intentions are physically stored in the log, the snapshots shown are only calculated and stored in memory on the nodes replaying the log.
In the following diagram we have removed the logical representation of the snapshots that annotate each intention. The physical version of these states is shown accurately as being stored in the database nodes (the series of blue circles, and the yellow latest committed state). In the next post of this series materialized views will be introduced, which are physical versions of these snapshots, and are stored in the log alongside intentions and other types of log entries.
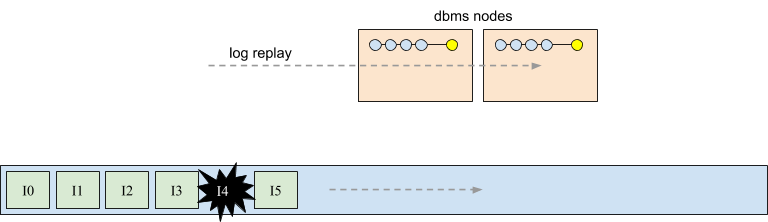
In a distributed setting, database nodes execute transactions and append intentions in exactly the same way as shown in the previous examples that discussed serial and concurrent intentions. In the following diagram both database nodes are appending intentions from transactions that have run locally, and independently on their respective nodes. Interestingly, there is no aspect of this operation that is different from the scenarios that we have already explored.
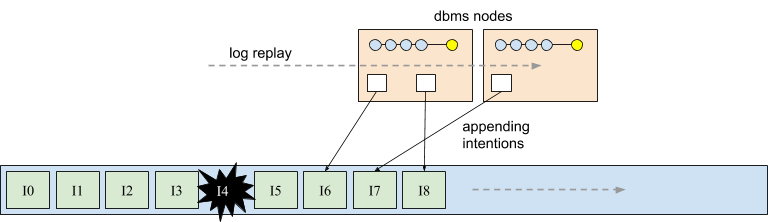
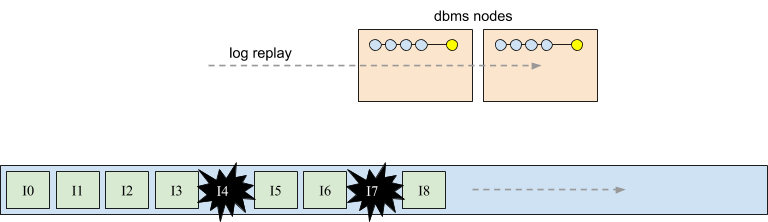
Completing the example, each database node will replay the log, observing intentions appended by other nodes, and make identical abort and commit decisions for each intention. For example, in the following diagram both database nodes will observe that I6 is a serial intention, that the concurrent intention I8 commits, and that I7 aborted due to a conflict. The resulting state is shown in the following diagram.
Looking forward
It would be nice if building a distributed database were as simple as this first post has made it appear. Unfortunately, a design based solely on a distributed log storing transaction intentions would be difficult to make high performance, among other real-world challenges. The following are some issues with the current design thus far presented that should be addressed:
-
When the log consists entirely of intentions, database nodes must maintain an entire copy of the database, otherwise each node would not have the required state upon which to replay an intention. For large databases, requiring every node to maintain a copy of the database may be a non-trivial resource requirement. This also has other implications such as requiring every node to participate in potentially expensive garbage collection maintenance.
-
The current design makes recovery an expensive operation consisting of replaying the entire log. While extensive log replay can be mitigated by building checkpoints, loading a large database checkpoint can be an expensive, high latency event. This would necessarily preclude deployment scenarios in which many lightweight clients are instantiated to interact with the database, a common scenario when database clients are embedded directly into applications.
-
Recall from the scenarios illustrated above that intention replay creates many fine-grained database snapshots that serve as immutable states used by future transactions. Additionally, as a transaction runs new versions of the database are being computed asynchronously through intention replay. Thus far the design presented does not address how these snapshots are created or managed.
In the next post we’ll discuss materialized views in CruzDB, a feature that addresses each of these concerns. Materialized views in CruzDB are fine-grained snapshots of the database which can be stored in the log, and are made accessible by all participants. Crucially, the views are created in such a way that each database node can efficiently recreate, on demand, any subset of any past state of the database. This means that not only can a node avoid storing the entire database, but large checkpoints do not have to be stored or loaded during startup, and transactions can simply reference a specific past materialized view by its position in the log to use as a snapshot.
Note that as stated, these snapshots also enable interesting features such as time travel in which any past database state can be examined. This is a particularly useful feature for performing analysis on a consistent state of the entire database. And since each snapshot is immutable, aggressive caching and optimization techniques can be used, even for long running queries, without interfering with new transactions.
And a special thanks to Jeff LeFevre for providing feedback and edits on this post.