Distributed logs have been receiving a lot of attention lately. And rightfully so—as a building block, they are a basic concept that in many instances can simplify the construction of distributed systems. But building a distributed log is no simple task. In this post I will share the design of zlog, our implementation of a globally consistent distributed log on top of Ceph. The implementation of zlog is based on the novel CORFU protocol for building high-performance distributed shared-logs.
A complete discussion of the log abstraction and its uses is far beyond the scope of this post. For an in-depth overview of logs and how they are used to construct distributed systems I highly recommend Jay Kreps’ post The Log: What every software engineer should know about real-time data’s unifying abstraction. While Kreps’ post discusses logs in general as well as how distributed logs (e.g. Kafka) are used at LinkedIn, in this post we focus exclusively on globally ordered logs; the type of log commonly built using consensus algorithms such as Paxos.
Our approach is based on the design of the high-throughput CORFU distributed shared log. Briefly, CORFU uses a cluster of flash devices onto which a logical log is striped, spreading I/O load across the cluster. Notably, the system is able to achieve high append rates using a few clever tricks that we will discus later. The following excerpt from the Tango system built on top of CORFU provides an excellent summary of the problem that CORFU solves:
The second problem with a shared log abstraction relates to scalability; existing implementations typically require appends to the log to be serialized through a primary server, effectively limiting the append throughput of the log to the I/O bandwidth of a single machine. This problem is eliminated by the CORFU protocol.
In the remainder of this post we will describe how the CORFU protocol works, and how we have mapped its concepts onto RADOS, the distributed object-store that powers Ceph. But first, why implement a distributed log like CORFU on top of a system like RADOS?
Two aspects of the CORFU system make its design attractive in the context of the RADOS storage system. First, CORFU assumes a cluster of flash devices because log-centric systems tend to have a larger percentage of random reads making it difficult to achieve high-performance with spinning disks. However, the speed of the underlying storage does not affect correctness. Thus, in a software-defined storage system such as Ceph a single implementation can transparently take advantage of any software or hardware upgrades, and make use of data management features such as tiering in RADOS, allowing users to freely choose between media types such as SSD, spinning disks, or future NVRAMs.
The second property of RADOS that makes it a great platform for implementing the CORFU protocol relates to the dependency CORFU places on the interface to storage devices. In order to enforce constraints defined within the CORFU protocol, storage devices are expected to expose a domain-specific interface specially designed for the protocol. While the authors of the CORFU paper describe both a host-based and FPGA-based solution, RADOS directly supports the concept of custom storage interfaces to its objects that can be used to achieve the transactional semantics necessary to implement the CORFU storage interfaces. This feature is called RADOS object classes, and is one of the most powerful features offered by RADOS for designing storage applications.
Next I’ll briefly describe the CORFU system, then go into detail on how it is mapped onto RADOS, and future enhancements to the implementation as well as applications that can be built on top of the system.
The CORFU Distributed Shared Log
So what is CORFU, anyway? It’s a high-performance, globally ordered, distributed shared-log. Addressing all of the nitty-gritty details of CORFU is beyond the scope of this post, so we will only touch on the overall architecture, salient features, and problems that CORFU solves. The following summary written by Peter Balis is a great description of the system and its power:
CORFU (Clusters of Raw Flash Units) is a system that exposes a cluster of servers loaded with flash drives as a high-throughput shared log abstraction. This is, in itself, a challenging distributed systems problem that the team solved elegantly via a mix of fast sequencing and clever protocol design. However, CORFU’s power is perhaps better demonstrated by Tango, a system the researchers built on top. Tango demonstrates how to build fault-tolerant, high-performance distributed data structures such as trees, maps, and serializable transactions by making efficient use of the shared log abstraction. This architecture is not only creative, but it’s a great use of modern hardware with excellent empirical results to boot
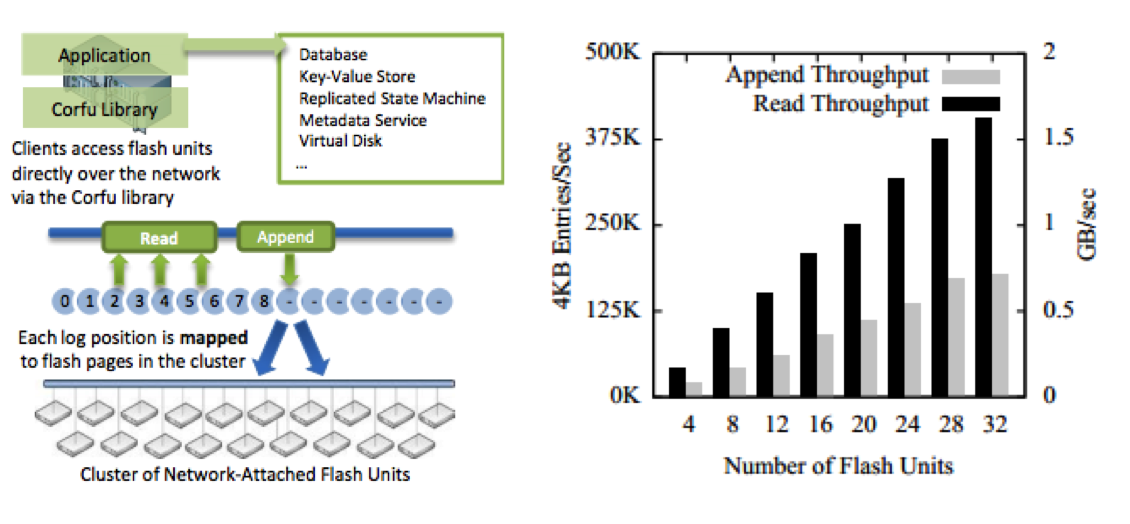
At a high-level the CORFU system contains two major components, shown below in the diagram that I have ‘‘borrowed’’ from the published CORFU paper for reference. First, a client library exposing a log abstraction is used to read and write from a logical log that is striped across a cluster of flash devices. The second component, the storage cluster, is composed of flash devices that export a custom networked interface that enforces properties required by the CORFU protocol. These two components alone are sufficient to support a consistent, globally ordered log, but without additional optimizations the system can’t scale to meet the needs of high-throughput applications. The graph below (also taken from the CORFU paper) shows the read and append performance the authors were able to achieve with 32 SSDs and 2x replication. Pretty good!
Next I’ll describe the interfaces in the system and the basics of the protocol without any optimizations. Then I’ll describe how the CORFU system uses a cache of the log’s tail position that is used to achieve high-throughput appends.
Storage Interface
The I/O operations on a log in CORFU are in terms of flash device pages.
The CORFU system depends on a domain-specific storage device interface
designed for the CORFU protocol for reading and writing log locations, as well
as maintenance operations. The following excerpt from the CORFU paper describes
the read, write, and trim components of the interface:
To provide single-copy semantics for the shared log, CORFU requires ‘write-once’ semantics on the flash unit’s address space. Reads on pages that have not yet been written should return an error code (error-unwritten). Writes on pages that have already been written should also return an error code (error-overwritten). In addition to reads and writes, flash units are also required to expose a trim command, allowing clients to indicate that the flash page is not in use anymore.
In addition to read, write, trim, a storage device is also used as a
coordination point for clients. The importance of this property will become
evident later in our discussion when we introduce a caching layer that allows
for high-throughput appends. Coordination is achieved using the seal primitive,
described in the paper as:
In addition, flash units are required to support a ‘seal’ command. Each incoming message to a flash unit is tagged with an epoch number. When a particular epoch number is sealed at a flash unit, it must reject all subsequent messages sent with an epoch equal or lower to the sealed epoch. In addition, the flash unit is expected to send back an acknowledgment for the seal command to the sealing entity, including the highest page offset that has been written on its address space thus far.
Note that trimmed positions cannot be re-used given the write-once semantics.
Thus, the storage device is expected to expose an infinite address space (in
practice a 64-bit address space is sufficient). In summary, storage
devices support random reads to previously written positions and write-once
semantics to any given position. Finally, trim allows clients to mark
positions as unused to support garbage collection, and a seal command is used
to install a new epoch value and discover the largest address written to the
device.
Client Library
A client library presents a log abstraction consisting of four operations, and
hides all of the low-level details related to the CORFU protocol as well as
access to the underlying storage
devices. Overall it looks like a typical log abstraction. The append method
adds an entry to the tail of the log and returns the position at which the
entry is stored. The read method returns the data stored at a given
position, or an error if the position has not yet been written. The trim
method is used by applications to mark log positions as unused, allowing the
system to reclaim space through a garbage collection mechanism. And finally,
the fill method is used to fill a log position with a junk value to ensure
that the position cannot be used.
Slow Append Operation
When a client wants to append to a log it must first find the tail. To do this a client may query each storage device in the cluster to discover the largest log position that has been written (recall from the description of the storage interface in the previous section that each device can be queried for its maximum position written). By taking the maximum position across all devices the tail can be discovered, and by writing to the next position the client will append to the end of the log. This process is referred to as slow tail finding, and clearly can’t scale to large clusters or support many clients. It’s really slow and painful. However, CORFU optimizes tail finding by introducing a network process called a sequencer that caches the tail to support high-throughput appends.
Tail Caching for Fast Appends
To address the scalability limits of the slow tail finding mechanism CORFU introduces a network server referred to as a sequencer. The sequencer caches the current tail as an in-memory counter and responds to client tail finding requests by first atomically incrementing the counter. By avoiding all I/O in the common case the sequencer is able to respond to tail finding requests at very high rates. If only it were this simple :)
There are three issues that need to be resolved that arise from the use of the sequencer as an optimization. First, the sequencer is theoretically a system bottleneck. The authors address this throughput limitation by observing that 1) their basic, non-optimized sequencer implementation was able to saturate the flash cluster at a rate of over 200,000 requests per second, and 2) each log in a system can use a distinct sequencer process. The second issue is that the sequencer appears to represent a single point of failure. However, as noted previously, the sequencer is only an optimization, and clients may always fall back to the slow tail finding mechanism. It is important to note that in practice clients never use the slow tail finding algorithm, and instead rely on a cluster of sequencers in combination with a leader election protocol to select a primary sequencer responsible for a log.
The third challenge with the use of a sequencer is the initialization of its in-memory counter. This is the most important challenge because it is directly related to the correctness of the system. Consider the scenario in which a sequencer is restarted but many clients have in-flight write operations. Since we cannot know the state of every client that has been previously granted a log position, what value should be used to initialize the counter in a new sequencer instance? The approach taken by CORFU is to execute the slow tail finding mechanism before a sequencer is brought online, while carefully ensuring that any in-flight client operations are invalidated by installing a new epoch value in each storage device. After this initialization process a sequencer will begin issuing new log positions tagged with a new epoch value, while any clients with in-flight operations will retry after contacting the new sequencer.
Storage Fault-tolerance in CORFU
The CORFU system is designed to run on top of raw flash devices. In order to achieve fault-tolerance and availability a form of chain replication is used to introduce data redundancy. The methods used to protect data in CORFU are largely orthogonal to the protocol used to achieve high-throughput appends. Since the RADOS storage system already solves the fault-tolerance and availability problem, we will omit a detailed discussion of this topic. Briefly, CORFU constructs redundancy groups to which log entries are replicated. By using chain replication and serving reads from the end of the chain consistency can be ensured. At a high-level CORFU simply treats each replication group as a durable storage target. Thus, a natural analogy to the CORFU replication group in RADOS is the placement group or object. Next we will discuss the mapping from CORFU to RADOS in detail.
A Distributed Shared Log on RADOS
So far we have seen how the CORFU system functions to achieve high-throughput appends to a globally ordered shared-log. Now we are going to discuss how the basic design of CORFU can be mapped onto Ceph. Specifically we are going to discuss the mapping of CORFU onto RADOS, a scalable, fault-tolerant object-based storage system that powers Ceph. Next I’ll give a brief overview of the salient features of RADOS that are important for this post, but a full discussion of the architecture of Ceph is beyond the scope of this post. There are plenty of resources for learning about Ceph, and I invite anyone not familiar with the technology to check them out!
Overview. The RADOS system is a distributed, scalable, and fault-tolerant object-based storage system that presents a cluster of unreliable nodes as a highly available object store. Each node is called as Object Storage Device (OSD) and is typically an off-the-shelf node with CPU, memory, and local disk. The RADOS system logically groups objects into placement groups and each placement group is assigned to one or more OSDs across which objects are stored redundantly (e.g. replication or erasure coding). Clients interact with RADOS through a library with a rich interface that completely hides the details of the underlying distributed system. A salient feature of RADOS that we make use of in this project is support for the injection of user-defined code for the creation of domain-specific transactional interfaces to object data that run within the cluster of storage devices.
Next I’ll discuss the layout of a log within RADOS, the custom storage interfaces designed for the CORFU protocol, and then present the client libraries and show examples of how easy it is to use the zlog implementation.
Logical Log Layout
In order to store a log in RADOS a choice must be made about how to assign log positions to addressable storage. For instance, each log position could be written to a dedicated object, or a single log could be striped across a fixed number of objects. Other strategies exist and each have different performance and implementation trade-offs, but that is a topic for a later post. However, for reasons related to bounding the slow tail finding mechanism, we’ve chosen a basic, initial implementation that stripes a log across a fixed (but adjustable across epochs) number of objects.
A log is defined by a stripe width parameter that specifies how many objects
the log should be striped across (a good choice is the number of placement
groups in the target storage pool). Each log position is mapped round-robin
onto this set of objects by the formula object-id = log-position % stripe-width. One might be tempted to think this would cause scalability
issues as an object grows in size, however, RADOS contains a wide variety of
object interfaces that allow us to access at a fine granularity both bulk and
structured data associated with an object, efficiently supporting access to
individual log positions even as the amount of data associated with an object
grows.
This mapping of log positions onto objects within RADOS is a direct analogy to the mapping of log positions in CORFU onto a set of SSDs organized into a redundancy group. Thus, the enforcement of the storage interface in CORFU must be achieved at the object level in RADOS. To accomplish this we use the object class feature of RADOS to install a custom interface that implements the interface expected by the CORFU protocol.
Zlog Custom Object Interface
The following code snippet shows the custom storage interface to objects in RADOS used to store log data. The ability to create custom object interfaces is a major feature of RADOS and you can learn more about it here.
First we have the set of possible return codes defined by our custom interface. Note that error handling is two-level. The outer layer is composed of RADOS specific errors (e.g. network errors or failures) and the inner layer is for our protocol. Thus, these codes are only valid when the outer layer reports success.
Note that below there are some RADOS specific items: the
ObjectWriteOperation can be thought of as just encoding the name of the
target object for the particular operation, the bufferlist is a fancy object
for holding binary data, and the data retrieved through cls_zlog_read is
accessed through the RADOS-specific ObjectReadOperation object.
/* Operation error codes. */
enum {
CLS_ZLOG_OK = 0x00,
CLS_ZLOG_STALE_EPOCH = 0x01,
CLS_ZLOG_READ_ONLY = 0x02,
CLS_ZLOG_NOT_WRITTEN = 0x03,
CLS_ZLOG_INVALIDATED = 0x04,
CLS_ZLOG_INVALID_EPOCH = 0x05,
};
/*
* Install a new epoch in an object.
*/
void cls_zlog_seal(librados::ObjectWriteOperation& op, uint64_t epoch);
/*
* Mark a log position as junk in an object.
*/
void cls_zlog_fill(librados::ObjectWriteOperation& op, uint64_t epoch,
uint64_t position);
/*
* Write to a log position in an object.
*/
void cls_zlog_write(librados::ObjectWriteOperation& op, uint64_t epoch,
uint64_t position, ceph::bufferlist& data);
/*
* Read the contents of a log position in an object.
*/
void cls_zlog_read(librados::ObjectReadOperation& op, uint64_t epoch,
uint65_t position);
/*
* Find the maximum log position written to an object.
*/
void cls_zlog_max_position(librados::ObjectReadOperation& op, uint64_t epoch,
uint64_t *pposition, int *pret);
The only substantial departure from the CORFU storage interface is that unlike
in the CORFU protocol, finding the maximum position is a separate operation
from seal which arises from certain limitations on what RADOS storage
interfaces can do. However, cls_zlog_max_position does enforce the last
sealed epoch, so when a new sequencer comes online and executes the slow tail
finding procedure it should first seal each object and then use the newly
installed epoch when querying for the maximum written position.
We now have enough detail on how the system is structured to describe the slow
tail finding procedure. First we need to seal each object that a log is
striped across, and then we’ll query for the maximum position written. In the
following code snippet, the for loop and slot_to_oid function implement log
striping, and for each object we construct and execute a seal operation
directed at the target object with the specified epoch.
int Log::Seal(uint64_t epoch)
{
for (int i = 0; i < stripe_size_; i++) {
std::string oid = slot_to_oid(i);
librados::ObjectWriteOperation op;
cls_zlog_seal(op, epoch);
int ret = ioctx_->operate(oid, &op);
if (ret != zlog::CLS_ZLOG_OK) {
std::cerr << "failed to seal object" << std::endl;
return ret;
}
}
return 0;
}
Once we’ve sealed each object that a log is striped across we use the newly installed epoch to query each object again for the maximum position that has been written. Note that since no existing client has knowledge of this new epoch value and each object rejects requests tagged with old epochs, we can be certain that once complete we have a guarantee on the maximum log position written across all objects.
Like before we loop over each object that the log is striped across. For each
object we construct and execute cls_zlog_max_position request. In the error
free case we simply record the maximum position seen and return this value to
the caller.
int Log::FindMaxPosition(uint64_t epoch, uint64_t *pposition)
{
uint64_t max_position = 0;
for (int i = 0; i < stripe_size_; i++) {
std::string oid = slot_to_oid(i);
librados::bufferlist bl;
librados::ObjectReadOperation op;
int op_ret;
uint64_t this_pos;
cls_zlog_max_position(op, epoch, &this_pos, &op_ret);
int ret = ioctx_->operate(oid, &op, &bl);
if (ret < 0) {
if (ret == -ENOENT) // no writes yet
continue;
std::cerr << "failed to find max pos " << ret << std::endl;
return ret;
}
if (op_ret == zlog::CLS_ZLOG_OK)
max_position = std::max(max_position, this_pos);
}
*pposition = max_position;
return 0;
}
And that’s it. A sequencer installs a new epoch and executes the slow tail finding procedure for each new log, and anytime a sequencer is restarted. The resulting position of the slow tail finding mechanism is what the sequencer uses to initialize its in-memory cache of a log’s tail. Next we’ll discuss the design of the sequencer used in our implementation.
Zlog Sequencer
There is a lot of flexibility in how the sequencer is implemented. All it needs to do is ensure that it can get a new epoch value, and that it seals all of the storage devices before starting to hand out log positions. Our current implementation is a standard Boost.ASIO asynchronous TCP server. It is capable of managing any number of logs stored in multiple RADOS pools. In the later section Epoch Management I discuss options for how the sequencer can acquire new epoch values. The code below shows the interface to the sequencer service, which contains only one important method to query (and optionally increment) the tail of a log.
class SeqrClient {
public:
SeqrClient(const char *host, const char *port) :
socket_(io_service_), host_(host), port_(port)
{}
void Connect();
/*
* Retrieve (and optionally increment) the tail position for a given log.
*/
int CheckTail(uint64_t epoch, const std::string& pool,
const std::string& name, uint64_t *position, bool next);
private:
/* ... boost stuff removed ... */
};
Log clients don’t interact with the sequencer directly, but rather indirectly through a client library that implements the log abstraction. For instance, the sequencer is contacted automatically when a client wants to append to the log.
Zlog Client Library
We now have all the bits and pieces necessary to demonstrate an end-to-end example. The following code shows the components of the log abstraction from the client library.
class Log {
public:
/* ... cut ... */
int Append(ceph::bufferlist& bl, uint64_t *pposition);
int Read(uint64_t position, ceph::bufferlist& bl);
int Trim(uint64_t position);
int Fill(uint64_t position);
/* ... cut ... */
}
The details of the log abstraction shown here were discussed in the previous
section on the CORFU system, so we’ll jump right into how this stuff is
implemented. The next code snippet is for the Append method that upon
successful completion returns to the caller the log position where the entry
has been stored.
The first step is to ask the sequencer what the current tail is. Specifically
we ask it to give us the next position in the log by first atomically
incrementing its in-memory counter using the CheckTail method of the
sequencer client library.
int Log::Append(ceph::bufferlist& data, uint64_t *pposition)
{
for (;;) {
uint64_t position;
int ret = CheckTail(&position, true);
if (ret)
return ret;
If successful, the sequencer will have given us the new tail position, so we
should be able to write to this location without any hassle. To do this we
construct a cls_zlog_write operation and execute it on the target object for
this log position.
librados::ObjectWriteOperation op;
zlog::cls_zlog_write(op, epoch_, position, data);
std::string oid = position_to_oid(position);
ret = ioctx_->operate(oid, &op);
if (ret < 0) {
std::cerr << "append: failed ret " << ret << std::endl;
return ret;
}
if (ret == zlog::CLS_ZLOG_OK) {
if (pposition)
*pposition = position;
return 0;
}
If no RADOS-level errors occurred (e.g. network errors) then we examine the
possible return values for our custom storage interface. First, if the
operation was successful we return the position to the client and we are done.
Otherwise there are two possible return values. First, we could been told by
the storage device that our epoch value is too old
(zlog::CLS_ZLOG_STALE_EPOCH). This can occur if the sequencer had to
restart, or if the log was reconfigured (e.g. the stripe width was changed).
The only other possible return value is that the log position has already been
written (zlog::CLS_ZLOG_READ_ONLY). This can occur if it was filled with
junk by another client to invalidate the position, or if following a sequencer
restart another client beat us to the punch.
if (ret == zlog::CLS_ZLOG_STALE_EPOCH) {
ret = RefreshProjection();
if (ret)
return ret;
continue;
}
assert(ret == zlog::CLS_ZLOG_READ_ONLY);
}
assert(0);
}
And that’s pretty much it. You can check out the rest of the implementation including the details of the custom storage interface on Github:
We’ll finish up this post with a basic example of how to use the interface, discuss some future work we’ll be looking at, and address the issue of dealing with epoch values.
Example
Assuming the sequencer service has been started, you’ll want to first create a connection to the sequencer using the sequencer client library:
zlog::SeqrClient seqr("localhost", "5678");
Next create a brand new log. A given log is striped across objects in a RADOS pool. When you create a new log provide a handle to the pool, as well as a striping width and a name for the log.
const int stripe_width = 100;
zlog::Log log;
zlog::Log::Create(ioctx, "mylog", stripe_width, &seqr, log);
Now the log is available to use. In the following code snippet a string is appended to the log which returns the position at which the string was stored. Finally the string at the reported position is read back and verified.
ceph::bufferlist bl_in;
bl_in.append("My first log entry");
uint64_t pos;
log.Append(bl_in, &pos);
ceph::bufferlist bl_out;
log.Read(pos, bl_out);
assert(bl_in == bl_out);
The current implementation places no restriction on the size of the log entries. For efficiency reasons future versions will provide options for using fixed-size log entries.
Epoch Management
Unique epoch values must be generated when a sequencer restarts or when a log is reconfigured, such as when the stripe width changes. The unique epoch value must be consistent and must be durable. Using any sort of service such as Paxos is sufficient. However, RADOS object operations are transactional and durable. We take advantage of this in our implementation in which we use a simple custom object interface that atomically increments a stored numeric value, allowing us avoid a dependency on another service.
What’s Next
There are a lot of directions we can go from here now that we have a basic proof-of-concept in place. Here are some possible avenues for future work.
Sequencer Clustering. Currently the system is tolerant to any races that exist in the presence of multiple active sequencers. However, there is no automatic fail-over for sequencers. The next step in this direction is to allow sequencers to be deployed in clusters and use a leader election protocol for sequencer master selection. This also requires adding a form of transparent connection hand-off so clients don’t observe connection failures with sequencer daemons.
Applications. The CORFU papers lists several target applications including database management system, key-value store, and replicated state machines. The Tango system was developed on top of CORFU in a later paper and described a framework for building metadata services. We have added a very basic proof-of-concept implementation of Tango in our zlog implementation, but it doesn’t yet contain all of the features described in the paper.
Benchmarking. We’ve done some preliminary benchmarking, but we don’t have access to a lot of hardware for large-scale testing. In general, depending on the setup, we’ve seen anywhere between 1000 and 7000 log appends per second for a single OSD. Currently Ceph isn’t optimized for this type of workload but there are active development efforts to reduce latency for small I/Os to LevelDB and RocksDB back-ends. We’ll also be exploring alternative storage back-ends with fixed-size log entries that should improve throughput and latency.