This is the third post in a series of articles exploring the architecture of CruzDB. In the previous post we saw how the copy-on-write tree structure used in CruzDB is serialized into the log, and today we’ll examine how intentions in the log are replayed to produce new versions of the database. We’ll see how transactions are analyzed to determine if they commit or abort, and also how metadata is stored in the database itself to accelerate the conflict analysis process.
Transaction life-cycle
When a transaction is first created it stores a reference to the database snapshot that it will read, which is typically the latest committed state known to the node where the transaction is started, but could be any committed snapshot. This is depicted in the diagram below labeled as step 1. Recall that a snapshot is immutable, so as the transaction runs it does not alter past state, but rather only produces a new state.
The next phase of a transaction is the execution of operations such as get, put, delete, etc… this is the application-specific part: inserting and updating records in the database. As the application is executing the transaction an intention and an afterimage are produced, labeled in the diagram as step 2. An intention contains a record of the operations that changed state (e.g. inserting a value), and depending on the isolation level, will also contain a record of the keys that were read from the snapshot. Both the intention and afterimage are constructed in memory, but can be paged out if they become too large.
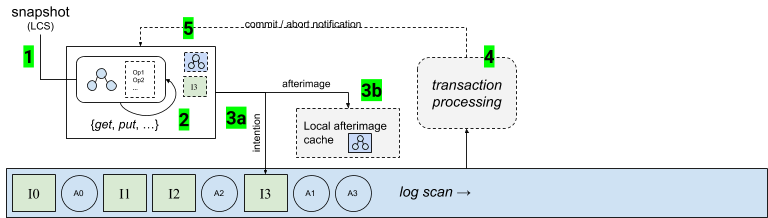
Operations on the transaction are finalized when the client tries to commit, but the transaction must be analyzed before a final commit or abort decision is made. The first step in this process is writing the intention to the log (step 3a). This is also the last moment at which the transaction may be aborted by the user, simply by not appending the intention, and discarding the transaction and any created state. A natural byproduct of transaction execution is an in-memory afterimage reflecting the state of the snapshot after applying the transaction operations. At the same time the intention is appended to the log, the afterimage is also moved into the local afterimage cache (step 3b). The afterimage cache is used to optimize intention processing when a serial intention is processed that originated from a local transaction, and will be discussed in more detail below when we discuss transaction processing.
As the intentions in the log are replayed, eventually the transaction processor will read and handle the intention (step 4) that was appended in step 3a after the transaction finished. The intention will be analyzed for conflicts to determine if the transaction commits or aborts. Once conflict analysis has completed, the application that started the transaction is notified of the final status of the intention (step 5). This marks the end of the transaction life cycle.
Next we’ll discuss in more detail how the transaction processor works. This corresponds to step 4 of the transaction life cycle as discussed above.
Transaction processing
Intentions are processed by CruzDB in strict log order by scanning the log and passing each intention to the transaction processor. Note that in general the log will contain other entry types in addition to intentions, such as afterimages. Afterimages that are encountered during log processing are handled by a separate afterimage management process which will be discussed in the next post. The following diagram shows the steps that the transaction processor performs for each intention, using intention I5 as an example of the intention currently being processed.
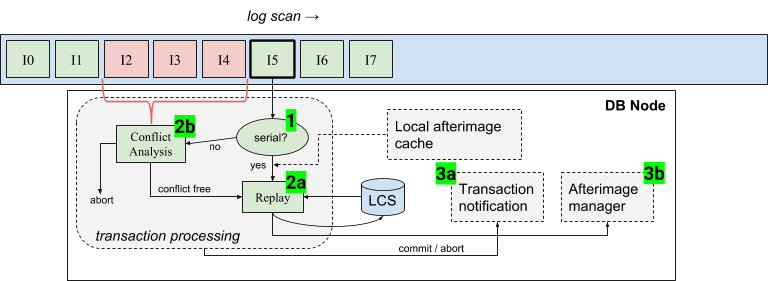
The following steps are implemented by the transaction processor. First an intention is examined to determine if it is serial (step 1). Recall that this determination is made by checking if the intention’s snapshot is the same as the latest committed state, which is as simple as comparing two integers representing the address of the respective snapshots. If the intention is serial then the intention is replayed against the current latest committed state, and the resulting tree becomes the new latest committed state (step 2a). If the intention is concurrent, then each intention in the conflict zone is analyzed (step 2b). If analysis determines that the intention experienced no conflicts, then it is replayed in the same way that a serial intention would be replayed (from step 2a), producing the new latest committed state. Otherwise, when an intention aborts the transaction processor discards the intention and any generated state. When a final commit decision is made about an intention, the transaction processor sends notifications to any transactions waiting on the result (step 3a). Finally, afterimages that correspond to committed intentions are sent to the afterimage manager which is responsible for ensuring that materialized views are written to the log (step 3b). Afterimage management will be discussed in the next post in this series.
Local afterimage cache
Note the component in the diagram labeled local after image cache. This cache is used to avoid replay of serial intentions when the resulting afterimage is available directly as a byproduct from a locally run transaction. This is a simple optimization that has little impact on performance for cache misses, but can significantly increase performance for single writer deployments with low concurrency. When the transaction processor is able to take advantage of a cached afterimage, it is able to completely avoid replaying the intention, and can instead simply reuse the afterimage produced by the transaction. Serial intentions are common when there is little contention for the log, which is a case that appears in certain applications.
Conflict analysis
Conflict analysis performed by the transaction processor involves determining if an intention conflicts with any other intention in its conflict zone. There are many strategies that can be used. The algorithm used for conflict analysis in the current version of CruzDB is straightforward, but non-optimal. The current algorithm implements a nested loop that compares the intention being analyzed (e.g. I0 below) to each of the intentions in its conflict zone. The following is representative of the current algorithm:
set K0 = {k : key in I0}
for each intention I in conflict zone
set KC = {k : key in I}
if intersects(K0, KC)
exit(abort)
endif
endfor
exit(commit)
The algorithm determines if a key in the intention being analyzed was written by an intention in the conflict zone. The real implementation handles write-write and read-write conflicts, but doesn’t yet record key ranges that were read in the intention used to handle additional isolation levels. Conflict analysis is one area that needs to be explored more closely. There are a lot of algorithmic options here, as well as basic engineering to increase performance.
Identifying conflict zone intentions
The conflict zone of a concurrent intention is defined as the set of committed intentions that exist in the log following the intention’s snapshot, up to the intention itself. However, given that intentions may abort and only committed intentions should be included in a conflict zone for analysis, it is necessary to be able to efficiently locate and identify only the intentions that commit within a range of zone addresses.
One method is to scan the entries from the log that are in the conflict zone range. For any intention in the conflict zone, if an afterimage also exists then it is implied that the intention committed and can be safely included in the conflict zone set. In this way the committed intentions can be found without replaying. However, in general we cannot prove that an intention aborted. The following diagram shows the conflict zone of a log in which I2 and I3 commit. Their afterimages are written shortly after the corresponding intentions, and would be found by scanning the conflict zone range.

But as shown in the diagram, the status of I4 is not easily known. While I4 does commit, its afterimage exists in the log after the conflict zone. This implies that scanning can take an arbitrary amount of work. But it’s worse than that. Even when scanning reaches the end of the log, afterimages for prior intentions may be in-flight. In practice afterimages are written quickly, but without some form of barrier, scanning to identify the intentions in a conflict zone is a poor approach that could block indefinitely. The solution CruzDB implements, which we will discuss next, is to maintain an index recording all committed intentions, which can be used to quickly identify the intentions in an arbitrary conflict zone range.
Committed intention catalog
In order to avoid scanning the conflict zone, CruzDB maintains a position index that records the location of all committed intentions. The committed intention index is stored in the database catalog (the catalog is also stored in the log as part of the persistent database state) as a sorted set of positions that correspond to every committed intention. When the intentions in a conflict zone need to be retrieved, the transaction processor opens an iterator to scan the conflict zone range. The resulting intention positions are dispatched to the I/O layer to be retrieved for analysis.
Building the committed intention index is straightforward. When the transaction processor determines that an intention will commit, it replays the intention to produce a new afterimage. This replay process is supplemented by introducing implied operations that update the afterimage. In this case, an implied operation is generated that inserts a single record into the committed intention catalog, recording the intention’s position. Since the generated operation is deterministic (i.e. the intention is always at a fixed location), it works as expected even in the presence of duplicate afterimages. Furthermore, it works well with a scanning approach, which may be preferred if it is known that a large percentage of the entries in a conflict zone region are cached in memory.
Inserting the implied records into the afterimage has the added benefit that they are automatically written into the log as part of the materialized views of the database without any other special handling, thus making the index available to other database nodes. It also simplifies the start-up process that must bootstrap the database state, and supports looking up the status of a transaction, such as when a client submitting a transaction has failed before being notified.
Caching the committed intention index
Although the committed intention index provides significant benefit over scanning the log, incurring the cost of iterating over this index, which may itself be paged out of memory, is a serious consideration for the performance sensitive transaction processor. However, we observe that in most cases transactions are short lived and their intentions are appended to the log promptly, resulting in conflict zones with ranges near the end of the log (we’ll discuss handling large conflict zones in a future post). Therefore, in order to further reduce the costs of locating intentions with a conflict zone CruzDB uses a cache that maintains a set of recently accessed committed intentions.
In the diagram below the transaction processor uses the cache to look-up intentions contained in a conflict zone. When a cache miss occurs the slower method of examining the index is used, and the resulting missing intentions are inserted into the cache. The cache may use an eviction policy (e.g. LRU), but eviction must ensure that intention ranges represented in the cache are not sparse in order to avoid false negatives.
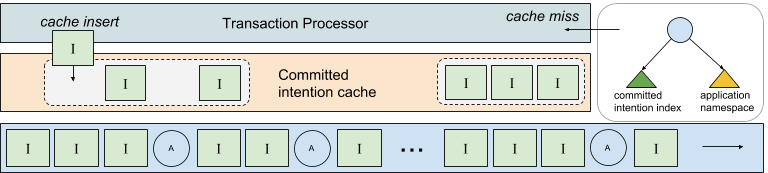
The current version of this cache only stores intention locations, and relies on caching within the log I/O layer to resolve cache hits to physical intentions without reading from the log.
In the next post we’ll learn about afterimage management, and how the new states produced by the transaction processor are serialized into the log. The discussion will contain important details about how the system achieves high throughput using parallel I/O and a pointer indirection index.
And a special thanks to Jeff LeFevre for providing feedback and edits on this post.