The CruzDB database system is a log-structured key-value store that provides serialized transactions over a distributed high-performance log. We have been working on this system for a little over a year and we just finished bindings for the YCSB workload generator. Today we’ll be previewing some of our initial performance results. We’ll cover some of the basics of the system, but will save a discussion of many of the technical details for another day.
The CruzDB database system is structured as a copy-on-write red-black tree where each new version of the tree is appended to a distributed log. New versions are created by executing a transaction over the latest version of the tree, and versions are stored compactly as an after image (i.e. delta) of the tree produced by the transaction. The interface is similar to that of the transactional interface of RocksDB. An LRU cache is used to store recently accessed parts of the database.
Log entries are immutable, so long running read queries do not affect writers and any number of read-only queries may run in parallel. The current implementation serializes all database updates, which limits transaction throughput. Batching and optimistic concurrency control are some of the next optimizations that we’ll be considering.
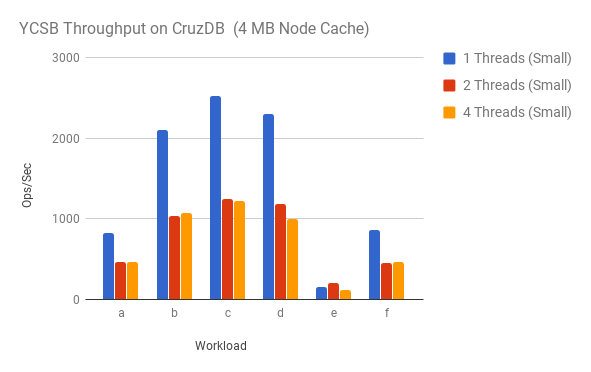
The first set of results show the overall throughput of the 6 default
workloads in YCSB for 1, 2, and 4 client threads. There are two results that
immediately stand out. First, the performance is relatively poor—we would
expect far more throughput for a workload like workload c which is a read-only
workload. The second observation is that adding more threads resulted in
lower throughput.
We’ll tackle the overall low throughput issue first. There are a number of reasons why throughput can be low, and we won’t look into all of them in this post, but a major factor is the cache miss rate. When the tree is being traversed, any node that is not in memory must be retrieved from the log storage. Presumably if we increase the size of the LRU node cache we should see better performance.
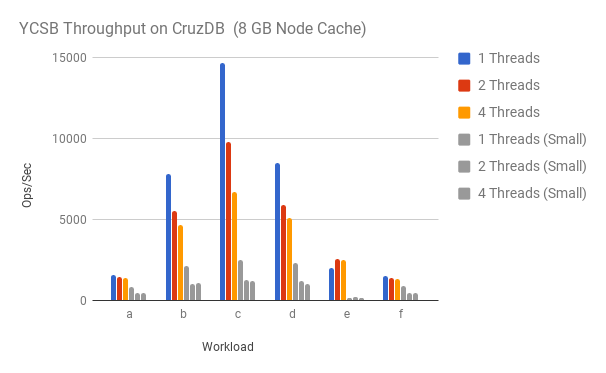
And indeed a larger node cache results is quite a bit better performance. For
the read-only workload c the throughput is nearly 6x better as can be seen
in the following graph. We plotted the results for the small cache for
comparison (shown in grey with label small).
The second issue with these results is the affect of additional client threads
on performance. While transactions that perform writes are serialized, we
would expect workloads like workload c to scale throughput with additional
threads as reads execute against a fixed snapshot and are not serialized.
However the affect of an additional client thread on the throughput of
workload c is quite detrimental.
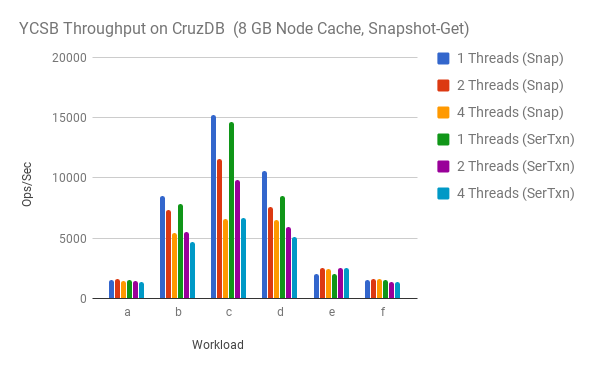
After some investigation I found that the CruzDB bindings to YCSB were running
each Get operation in a transaction, and CruzDB currently doesn’t have a smart
read-only transaction. We implemented a new version of the Get binding that
runs against a snapshot, rather than in a serialized transaction. The results
of the optimization are shown in the graph below. The runs labeled Snap are
for the optimization and the runs labeled SerTxn are the original serialized
transaction approach.
Looking at workload c the performance of a single thread is slightly better
with the snapshot-based Get operation, and the performance hit taken with
additional threads is not as severe, which is the trend we were expecting.
The effect doesn’t seem to be present with 4 threads, nor is it a dramatic
improvement. Given this result I expect to be able to find the source of the
performance degradation elsewhere.
The remaining issues are related to the multi-threaded cases. First, for a
read-only workload like workload c why is there any performance hit with
more than one thread? The two threads are running in parallel with
snapshot-based Get operations, and assuming that there are no cache misses
with an 8GB node cache, I expect the source of this overhead to be related to
both locking in the database (e.g. the node cache), as well as the hit
we are taking from our heavy use of smart pointers and the associated
overheads they introduce.
Another issue is that for write heavy workloads, it is curious that the performance hit for multiple threads is so high, even when considering that transactions are serialized. There are multiple threads that synchronize with each other during transaction processing, and this may be a cost that we see when multiplied by a large number of transactions in the form of thread wake-up latency.
And finally, the performance of workload e, in particular, is very surprising.
This is a workload that is 95% scans (that run in parallel against a
snapshot), and 5% inserts (that are serialized). I would have expected that
the performance here is much better given the high percentage of operations
that may run in parallel. This may be explained by the fact that a single scan
does a lot of work, but counts as a single operation.
Stay tuned for more. We’ll be looking in depth at these queries, and in the near future we’ll be prototyping a group commit feature that should significantly increase the write throughput.