In Adding a new placement group operation in Ceph I demonstrated how to add a new operation in RADOS that operates at the placement group level, allowing one operation to operate on multiple objects. Recently I’ve been experimenting more with operations at the placement group level, and found interesting performance behavior when reading multiple objects within a single PG operation.
The two graphs below show the results of four experiments that each read 1000
small objects from a placement group with eight PGs. In one experiment
cls_coldcache and cls_hotcache each of the 1000 objects is read
sequentially by a client, making 1000 network round trips. The test is
repeated with a hot cache and a cold cache (Linux drop_cache plus OSD restart).
In the second pair of experiments pg_coldcache and pg_hotcache a client
makes a call to each placement group which in turn reads all of its objects
and returns a blob containing the concatenation of all the objects in that
placement group.
Note that these latency measurements are taken at the lowest level in Ceph,
right before pread jumps into the kernel, so they do not include all of the
other overheads of OSD code paths or network affects.
The first graph shows the hot cache case. When we look at the hot cache case each read in either version is fairly cheap, but the placement group version wins, likely due to the fact that we are reducing network round trips by around 1000x. This result for the hot cache case is not really surprising.
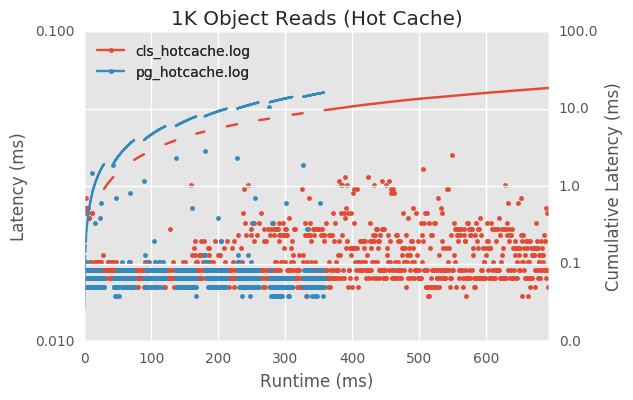
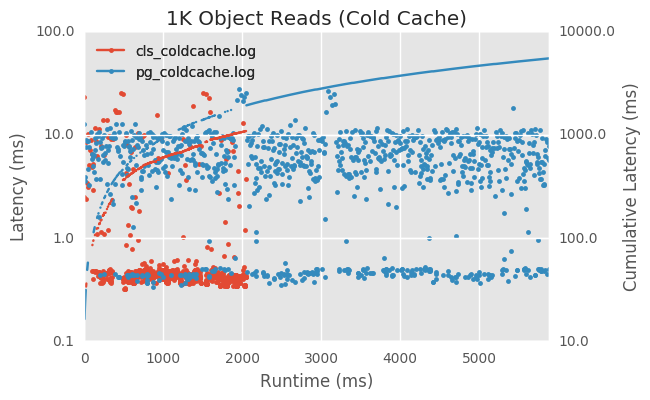
But the second graph shows the cold cache case. The important thing to notice is
that even with 1000 separate read operations dispatched from the client the
normal read path is much faster (2 seconds vs 6 seconds). The latency of each
read operation is significantly higher when reading from the do_pg_op
context.
The only thing that I can come up with that would explain the behavior is some sort of pre-fetching. However as of now I have not yet been able to find any place in the OSD where this pre-fetching is occurring.
The search continues…