In our previous post on CruzDB performance we examined initial performance results for the YCSB benchmark. The results showed that a larger cache had a significant benefit for performance (no surprise), but we also observed that even for read-only workloads throughput was not scaling with the number of threads. In this post we address this issue and present new scalability results.
CruzDB is structured as a copy-on-write red-black tree where every new version is stored in an underlying shared-log. Transactions in CruzDB execute against a snapshot of the database, and when a portion of the tree is not resident in memory it can be reconstructed by reading the missing data from the underlying log in persistent storage.
When memory pressure is high a portion of the tree can be removed. However, since there may be many references to a single node in the tree, we cannot atomically remove the node and all its references. Thus, after removing a link in the tree, a racing thread may attempt to reconstruct this missing portion of the tree even though that portion is already in memory. To avoid copies of a sub-tree from being created we use a node cache on top of the log. The cache is organized as an LRU cache, so it also serves as an indicator of what parts of the tree should be removed.
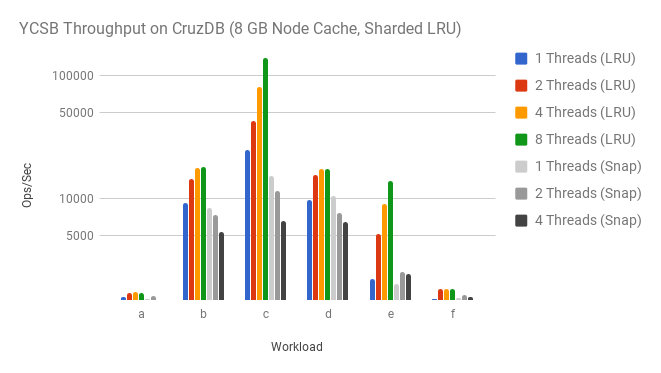
The read scalability issue shown in the previous post
was found to be caused from a contended lock in the node cache. Through a
basic sharding strategy we were able to reduce contention and achieve better read
scalability. The following graph compares the new sharded LRU optimization
(labeled LRU) to the previous optimization (labeled: Snap). This graph is
log scale because sharding the LRU cache gave an extra order of magnitude
increase in throughput for the read-only YCSB workload c. Other mixed
workloads also fair better.
There are a lot more optimization strategies that we can introduce to
increase read throughput. Instead of deep diving on read performance, we’ll be
adding a group commit feature that will increase update transaction
throughput across all workloads (accept c which is read-only), especially
a and f.