This post provides an update on the ZLog project, including the latest performance enhancements, and where we are heading next. If you aren’t familiar with ZLog it is a high-performance distributed shared-log. It is unique in that it maintains serializability while providing high append throughput, which makes it an ideal candidate in building things like replicated state-machines, distributed block devices, and databases.
The design of ZLog is based on the CORFU protocol, but adapted for a software-defined storage environment. In our case this environment is the Ceph distributed storage system. For a lot more information about the motivation behind ZLog and how it is mapped onto Ceph please check out this previous post on the design of ZLog.
CROSS Funding
Last year the ZLog project was selected for funding by the new Center for Research in Open Source Software (CROSS), an organization at the University of California, Santa Cruz that funds research projects with potential for making open-source contributions. Since funding has started we’ve had numerous students contribute to ZLog, as well as providing funding for myself to expand and further develop the project. The ZLog project is development in the open on GitHub.
ZLog Version 2: Design and Performance
Up until recently there has been a single implementation of ZLog (version 1), and now we are excited to debut the second version of ZLog which provides a significant performance boost over version 1. In the remainder of this post I’ll describe the two versions, and preview the upcoming version 3 which offers further performance improvement.
Performance Results
The design of ZLog stripes a logical log across a set of Ceph object storage devices avoiding coordination in the common fast path. We provide here the result of performance benchmarks run on a single OSD. The ZLog implementation is based on the Jewel release and we use the default configuration of Ceph with the FileStore backend. The hardware is an HP Proliant system, with two high-performance NVMe devices generously contributed by CROSS founding member SK Hynix.
- 2x 6-Core Xeon E5-2630
- 64 GB DDR3 RAM
- 2x 1TB SK Hynix M.2 NVMe (3D NAND)
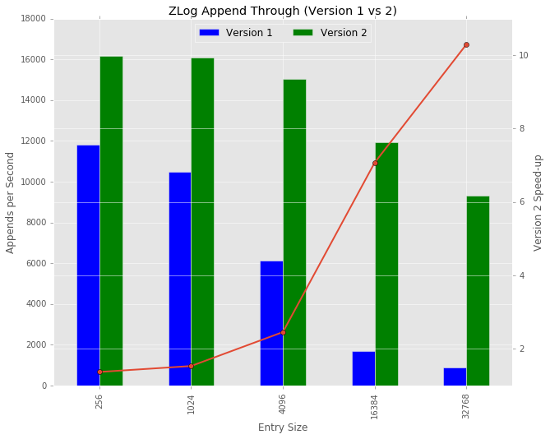
The following graph summarizes the performance results for a range of log entry sizes. Small entries of 256 bytes see a speed-up of 1.36 using ZLog version 2, and users writing 4K entries will see a speed-up of 2.45. The performance difference between version 1 and version 2 becomes large with increasing entry sizes where we observe a speed-up of 10.3 for 32KB entries. This isn’t surprising, given that version 1 stores log entries in LevelDB or RocksDB which are not optimized for storing large values. However, version 2 introduced many implementation challenges that forced us to work with the less performant version 1 until recently.
Design Overview
Version 1 of the ZLog stripes a log (an ordered set of blob entries) across a fixed set of objects in Ceph. This set is referred to a stripe. Within an object each entry (both the bytes associated with the entry, and metadata maintained by ZLog) is stored in LevelDB or RocksDB (the omap interface in RADOS). Since omap can grow without bound, there is little benefit to ever changing the stripe (in practice it can be expanded or shrunk to handle cluster hardware changes). The primary impact of this design on performance can be observed by the graph above: large entry appends perform poorly due to the limitations of the underlying key-value database.
Version 2 decouples metadata management from log entry management, keeping all values in LevelDB or RocksDB small, and storing the variable sized log entries in a bytestream interface (e.g. a POSIX file). This significantly increases performance, especially for large log entries. However, this design also introduces implementation challenges that extend into the client itself: when objects grow too large a new stripe must be created. Coordinating this among clients has been a challenge, but the current implementation is stable and has been running now for some time.
Next Steps
The final version of ZLog that we will be investigating in the coming months completely eliminates the use of LevelDB and RocksDB, using instead a very compact in-memory index. Through a proof-of-concept implementation we have seen nearly double the performance over version 2, but the implementation requires modifications to Ceph itself and will take some time to implement.