A powerful feature of Ceph/RADOS is its ability to atomically execute multiple operations on a single object. For instance, object writes can be combined with updates to a secondary index, and RADOS will guarantee consistency by applying the updates in a transactional context. This functionality is used extensively to construct domain-specific interfaces in projects such as the RADOS-Gateway and RBD.
This transactional capability can also make it easier to construct distributed applications through the use of custom interfaces, a simple example being an atomic compare-and-swap primitive. Another common building block in distributed systems is the use of an epoch as a guard on operations, or as an identifier of the current system state. For instance a client whose epoch is found to be too old will retry its operation once it has refreshed its view of the system. A recent example of a system that uses this approach is the CORFU distributed, shared-log, in which storage devices reject writes that are tagged with an expired epoch.
The following pseudo-code illustrates an object class in RADOS that implements a guarded append operation:
func append(epoch, payload)
cur_epoch = lookup("epoch_key")
if (epoch < cur_epoch)
return STALE_EPOCH
else
append(payload)
return OK
end
Guarded-append Benchmark
In order to test the performance of this interface we can simulate it by using the ability of the librados::ObjectOperation to perform compound operations. The code snippet below shows the essence of the benchmark we used to test the performance of the guarded write interface shown above. The operation appends a 4K buffer, and performs an equality test on an omap index value, both of which are executed remotely on the OSD in a transactional context.
for (;;) {
librados::ObjectWriteOperation op;
op.append(bl); // 4K blob
op.omap_cmp(asserts, NULL); // Simulate epoch guard
ioctx.operate("obj", &op);
}
The workload is repeated twice, once with and without the epoch guard, and for a variable number of clients. Note that all clients are writing to the same object. In practice writes will striped over a fixed set of objects, roughly within a single epoch, so this workload represents a worse-case, but with a large number of clients this shouldn’t be an unreasonable approximation of the workload.
The charts below show the throughput and latency of the append-only, and the guarded append workloads while we vary the number of client threads. The tests were performed on a single OSD using an SSD as a journal, and an HDD for the data drive. In the first set of charts parallel journaling was not enabled. Notably, the throughput of the append-only workload scales up to around 1600 ops/sec with 32 clients writing, while the performance of the guarded append workload maxes out at less than 400 ops/sec, and with significantly higher latencies. Why is the performance of the append with a guard so terrible? This is most likely because each operation simultaneously dirties an object and performs a read. Since reads are satisfied from the data drive, this effectively serializes all the operations. So much for that SSD?
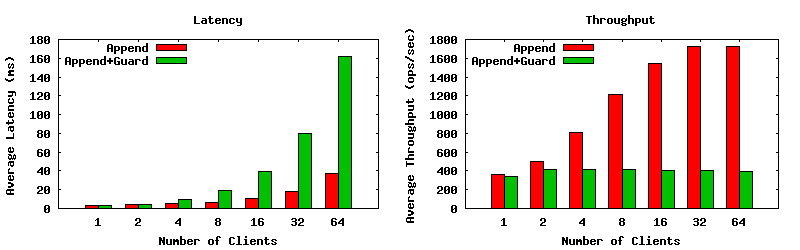
In contrast, parallel journaling mode will send ops to both the journal and data drives simultaneously. If everything succeeds on the data drive, it means that reads can be satisfied sooner. Thing improve a bit, but they still level off after about 8 clients.
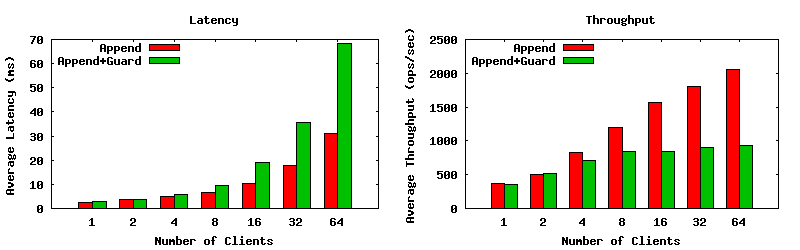
Solutions
While this post addresses a narrow use case, in general it would be useful to be able to efficiently read from objects recently written without always having to flush updates to the data drive (if that is indeed what is happening here), for instance being able to resolve updates in memory to serve reads. Here are some solutions that address only the issue of handling easily cached data elements. Two potential solutions come to mind, the first being rather general, while the second exploits the fact that the epoch changes rarely, making it a prime candidate for aggressive caching:
-
If the reason for the performance problem is that each epoch read requires first flushing the journal, tracking object dirty state at a finer granularity could avoid the flushing that results from the epoch read. However, this may be a quite invasive change, and doesn’t allow for further optimizations such as caching the epoch value in memory.
-
Allow object classes to cache data. This is a very attractive solution because it allows us to avoid doing any I/O. However, the current object class interface won’t allow this because the state of the encapsulating transaction is unknown to the interface, making it difficult or impossible to keep the cache consistent with the actual state on disk. By expanding the object class interface to support a callback indicating the final state of the current transaction, object classes would be able to perform their own caching.
Solution 1 above is likely a quite complex engineering task, and while 2 is helpful here, both techniques would be useful in general. In practice, the solution to this entire problem is to use more objects :)